



Why build Microservices with Domain Driven Design?
And what really is Domain Driven Design?


One of the biggest challenges in building microservices is determining the boundaries of various services. The common wisdom is to keep the service boundaries in sync with the overall domain boundaries.
This is where Domain Driven Design (also known as DDD) becomes extremely useful. In today’s post, we will look at the most important concepts of Domain Driven Design. Also, we will understand why DDD is probably the best way to build microservices.
Domain Driven Design helps fulfil the desire to have our programs better represent the real world in which they operate. Object-Oriented programming languages have been trying to bridge this gap for years. However, simply using a programming language is not enough to achieve code and real world correlation.
This is where Domain Driven Design steps in.
To understand how DDD can help with the goal, we need to understand some important concepts:
- Ubiquitous Language - Defining and adopting a common language to be used in code as well as in describing the domain. This aids communication between business analysts and developers.
- Aggregate - Collection of objects that are managed as a single entity and refer to real-world concepts.
- Bounded Context - An explicit boundary within a business domain that provides some functionality to the wider system and hides the underlying complexity.
Let us look at these terms in greater detail.
Ubiquitous Language
This concept stems from the idea that we should strive to use the same terms in our code as the end-users of our application do.
A common language between delivery team and the business users makes it easier to model the real-world domain. It also improves communication.
Usually, the data model is built with generic terminologies. Over time, the entire code-base gets polluted with such terminologies. For example, in a typical credit system, there could be several types of collateral agreements such as property, vehicles, inventory. However, within the code-base, they are all treated as a generic agreement type.
This makes life tough for developers since they have to try and map the rich domain language of the business owner to generic code concepts. Even business analysts have to spend a lot of time simply explaining the same concepts to the development team. This is a lot of unnecessary work.
If we can work the real-world language into the code, developers can easily pick stories written using business terms. They are more likely to understand the meaning of the terms and what should be done in terms of code changes to handle the changes.
All in all, this can result in increased productivity as well as improved correlation between business terminologies and the actual source code.
Aggregate
Aggregate is basically the representation of a real-world domain concept. In the context of an e-commerce store such as Amazon, think of the aggregate as something like an Order, an Invoice, or an Inventory Item.
Generally, an aggregate has state, identity and a life cycle that is managed in the system. We can practically implement an aggregate like a state machine.
Aggregates are also self contained units within the application. The code handling state transitions of an aggregate is grouped together with the state. Basically, one aggregate should always be managed by one microservice only. However, it is quite okay to have a particular microservice handling multiple aggregates.
If another service wants to change an aggregate belonging to some other service, it can take the below options:
Directly request a change in that aggregate through a well-defined interface.
Make the aggregate react to the other things in the system to initiate a state transition. This can be done by the aggregate subscribing to events issued by other microservices.
An aggregate can also say no to outside change or a transition request. What this means is that an aggregate should be able to determine in case a particular state transition is illegal.
Aggregates can have relationships with other aggregates. For example, a Customer aggregate can be related to one or more Orders or one or more Wishlists. The other aggregates can be managed by the same microservice or by a different microservice. See below illustration:
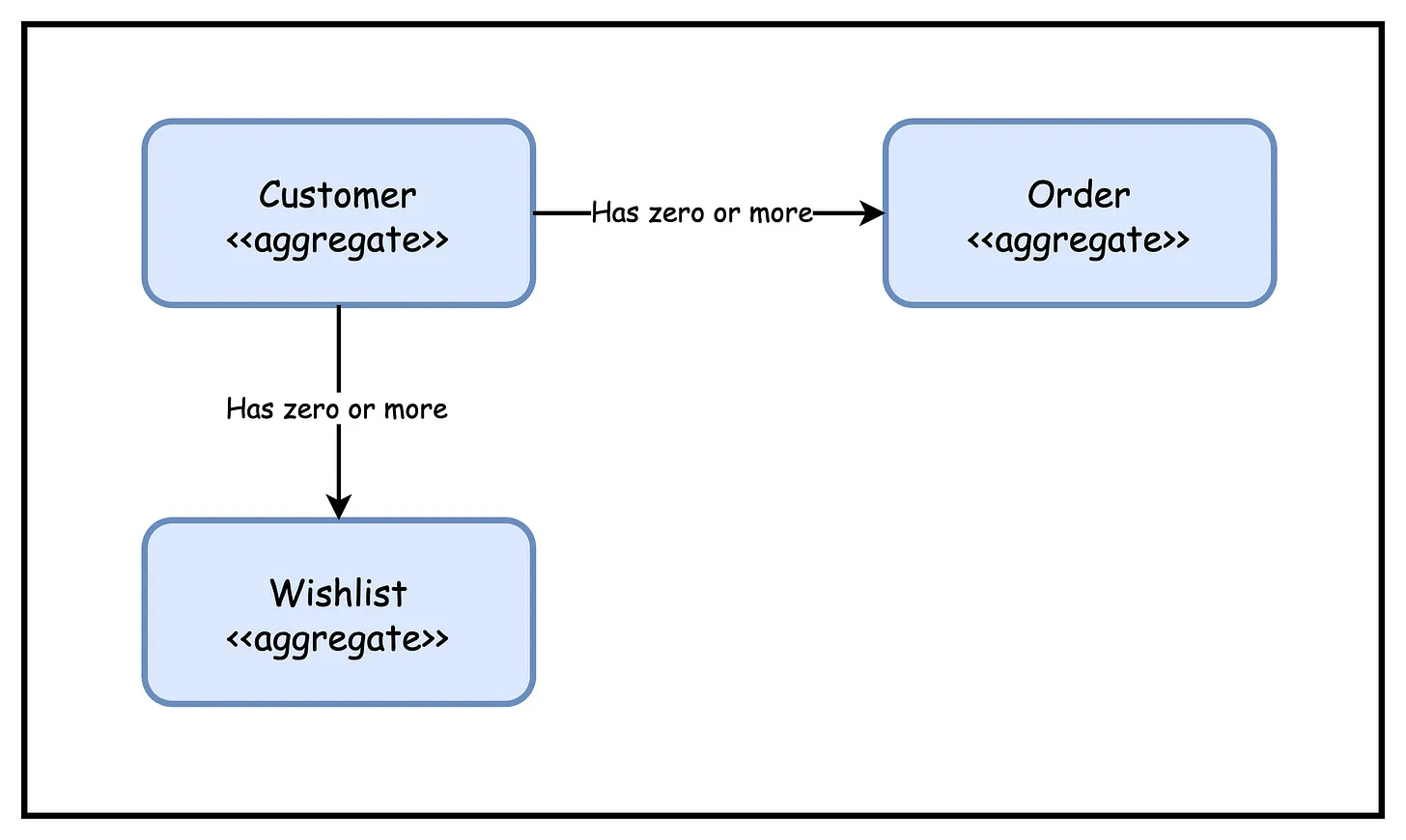
How can we maintain these relationships between aggregates?
If a relationship exists within the scope of a single microservice, we can manage it by storing a foreign reference in a relational database.
However, if relationships between aggregates span service boundaries, we need a different modeling approach.
In option 1, we store the ID of the related aggregate directly in the local database. For example, if the Order aggregate was in a different microservice to the Custom aggregate, we could establish a relationship between the two by having a customer id column within the order table. To get more information about the customer within the order microservice, we need to call the customer microservice using the customer id. Basically, the relationship in this case is not explicit but implicit.
In option 2, we can try to make things more explicit by storing a URI (such as customer/287) instead of a vanilla customer id. While this practice of building a URI is followed by some organizations, this could also be considered an overkill. In my opinion, this is not a great way of representing data in the table as it makes the assumption that we are using a REST-based architecture.
Bounded Context
Bounded Context represents a larger organizational boundary. Within the scope of the boundary, there are explicit responsibilities that need to be performed.
For example, in a typical Amazon warehouse, there is a lot of activity around managing orders being shipped, handling returns, taking delivery of stock. The Invoice department of Amazon handles creation of invoices, collecting payments. Basically, these are two separate bounded contexts within the overall system of delivering items to users.
Bounded contexts hide implementation details. From an implementation point of view, a bounded context can contain one or more aggregates. Some aggregates may be exposed outside the bounded context as well. Others may remain internal to the context. Also, bounded contexts can have relationships with other bounded contexts.
These relationships between bounded contexts can take place using a shared model of some sort. See below illustration:
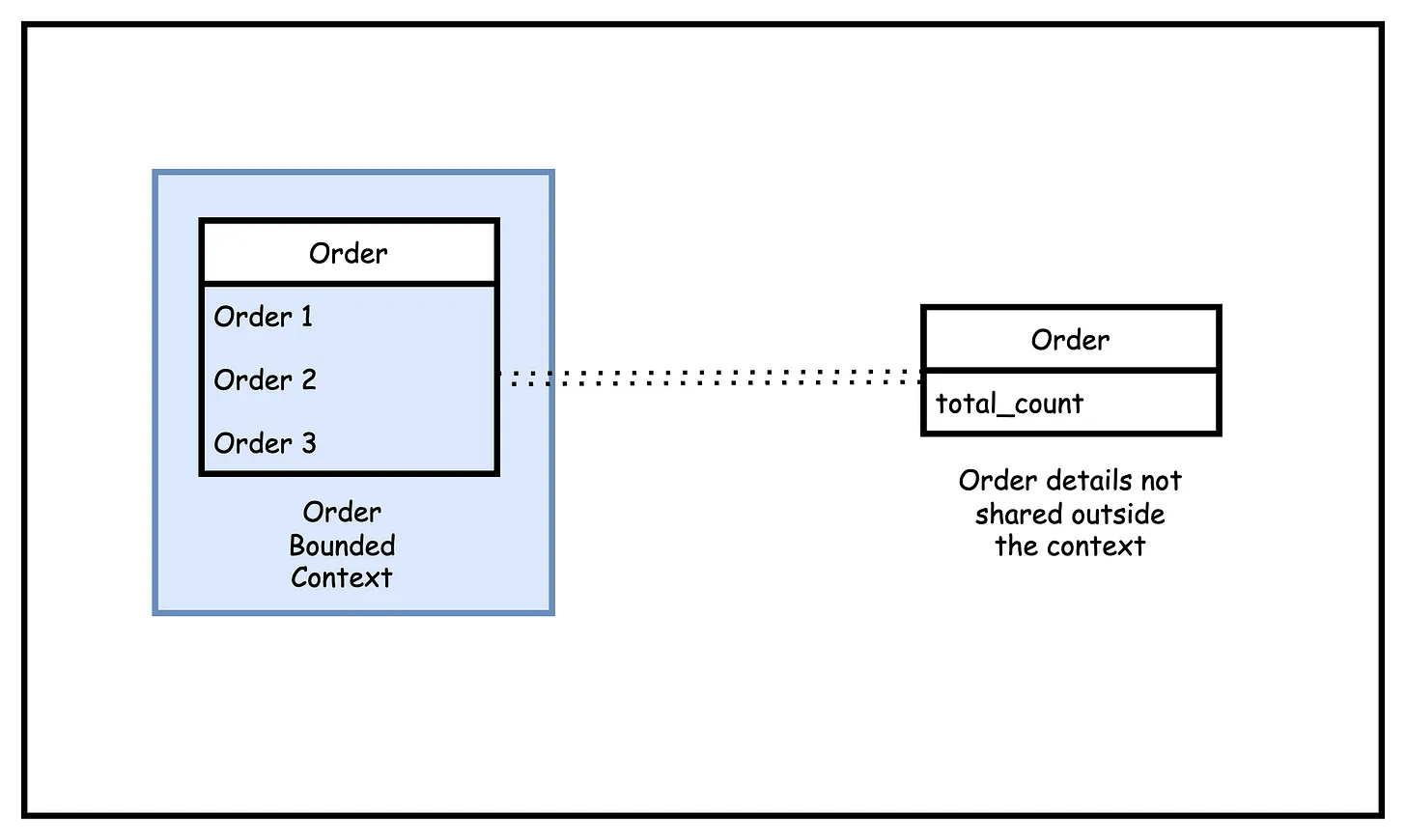
For example, we may have separate bounded contexts for Customer and Order. In the customer information, we may want to show the number of open orders for a customer. In such a case, we can have the order_count for a customer as a shared model between the two bounded contexts. The entire order model is not needed.
Mapping Aggregates and Bounded Contexts to Microservices
Both aggregates and bounded context are units of cohesion with well-defined interfaces.
Aggregates can be considered as self-contained state machine that focus on a single domain concept.
Bounded Context is a collection of associated aggregates with an explicit interface to the wider world.
In reality, both aggregates and bounded contexts can work quite well as service boundaries. Initially, it might be a better idea to target entire bounded contexts as microservices.
The advantage of this approach is that once you have a well-defined service boundary for a bounded context, you can easily split the internal logic into multiple services later on. Since the inner workings of a bounded context are isolated from the outer world, any refactoring of services does not create an impact outside as long as the service interface does not change.
As discussed earlier, important point to remember is that one microservice can manage one or more aggregates but one aggregate should not be managed by more than one microservice.
What makes DDD well suited to Microservices?
After going through the core concepts of Domain Driven Design, we can pretty much conclude on how DDD is well suited to build a microservices architecture.
- Firstly, bounded contexts are very important to DDD. Bounded contexts are all about hiding information and presenting a clear boundary to the wider system. The contexts hide internal complexity that can change over time without impacting the rest of the system. When we follow domain driven design, we are basically adopting information hiding resulting in stable boundaries for our microservices.
- Secondly, by focusing on a common and ubiquitous language, we are able to follow a shared vocabulary. This helps define API endpoints and event formats that closely match the domain. Ultimately, this makes our application’s service layer easier to understand and consume.
- Third, DDD puts the business domain at the heart of software. It encourages us to pull the language of the business into our code and service design. This indirectly improves the domain expertise among the developers who actually build and maintain the software.
To conclude, domain driven design is a great methodology to follow when working on microservices architecture. On a high-level, it gives a lot of structure to our application and makes it much more domain-oriented in the long run.
What do you think about Domain Driven Design? Have you had the chance of using it in your own projects? And if yes, did you find it beneficial?
Do share your views in the comments section below. Also, if this post was useful, consider sharing it with your friends or colleagues.